bs模块
from bs4 import BeautifulSoup
解析器
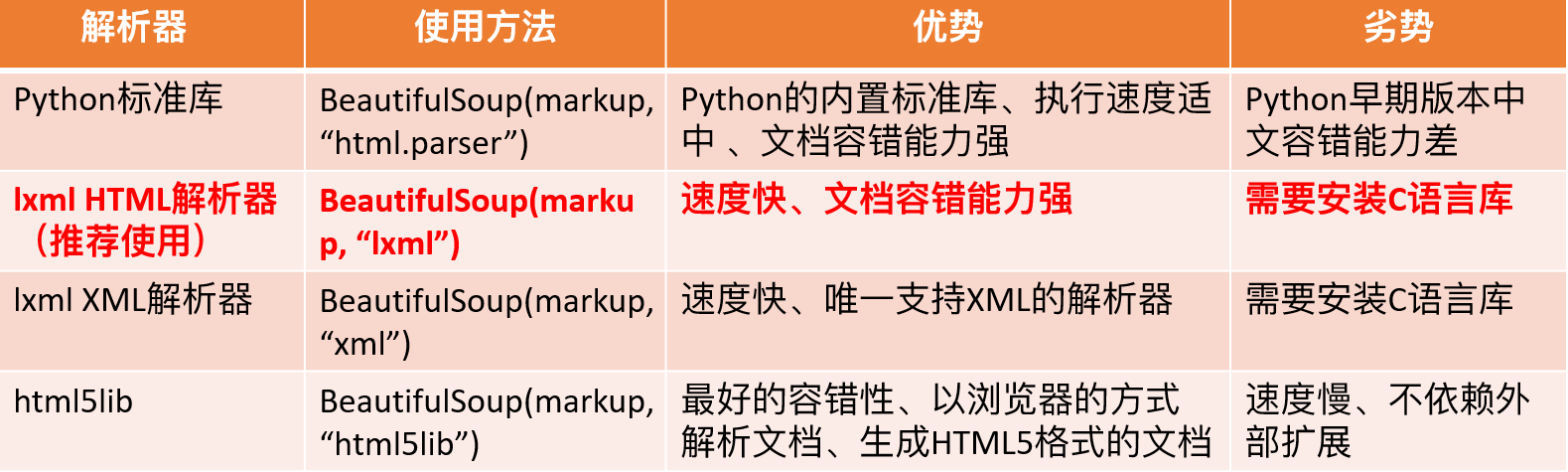
lxml HTML 解析器下的选择器
标签选择器
•选择元素、获取名称、获取属性、获取内容、嵌套选择、子节点和子孙节点、父节点和祖先节点、兄弟节点
•soup.prettify()、soup.title.name、soup.head、soup.p.string、soup.p[‘name’]
标准选择器
•soup.find_all(‘ul’)、find_parents()、find_next_siblings()、find_previous_siblings()
•soup.find(‘ul’)、find_parent()、find_next_sibling()、find_previous_sibling()
CSS选择器
soup.select()、soup.select_one()直接传入选择器参数 [.代表class,#代表id]
1
2
3
4
5
6
7
| soup.select('.panel .panel-heading')
soup.select('ul li')
soup.select('#list-2 .element')
ul = soup.select('ul')[0]
uid = ul['id']
trs = soup.select('table tbody tr')
title = trs[0].select_one('td a').text
|
一个样例
1
2
3
4
5
6
7
8
9
10
11
| url = ''
resp = requests.get(url)
page = BeautifulSoup(resp.text, "lxml")
table = page.find("table", attrs={"class": "hq_table"})
|
一个实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| """
7.12 Kevin
优美图库 唯美壁纸 BeautifulSoup解析实例
"""
import requests
from bs4 import BeautifulSoup
url = 'https://www.umei.cc/bizhitupian/weimeibizhi/'
resp = requests.get(url)
resp.encoding = 'utf-8'
page = BeautifulSoup(resp.text, "lxml")
a_list = page.find("ul", class_="pic-list after").find_all("a")
for a in a_list:
curl = 'https://www.umei.cc'+a.get('href')
resp2 = requests.get(curl)
resp2.encoding = 'utf-8'
page2 = BeautifulSoup(resp2.text, "lxml")
src = page2.find("section", class_="img-content").find("img").get('src')
img_name = src.split('/')[-1]
src = requests.get(src)
with open("img/"+img_name, 'wb') as fw:
fw.write(src.content)
print(img_name, "over!")
|

