1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| """
7.14 Kevin
网易云音乐 热评 爬虫
"""
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json
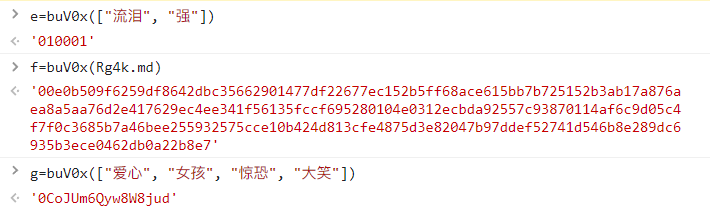
d = '010001'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g = '0CoJUm6Qyw8W8jud'
i = "kyM74e2babr6Ktf3"
data = {
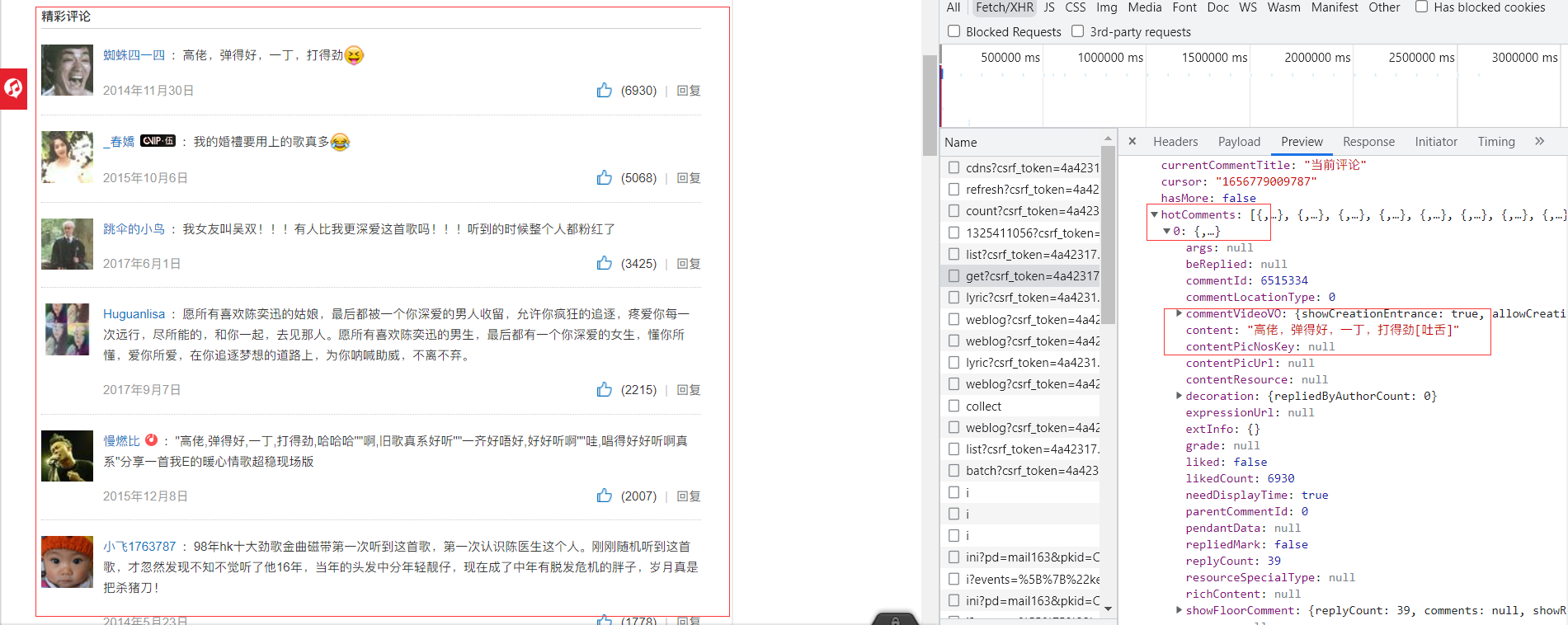
"rid": "R_SO_4_28160882",
"threadId": "R_SO_4_28160882",
"pageNo": "1",
"pageSize": "20",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"csrf_token": "4a42317491b25188649cd33d5ccfe8c4"
}
def get_encSecKey():
return "5015aaf2b9d0c1487908bf12cd0afdac506c4e7527cb6805ead6f4f6fa363aed69d876a0a9ecf18caaadc09ff9a61dcbf868657e15bbd0a24a44c41b499e19d5e9eede71d3f99232f965515aef8fc282f15b7ee7816fd9b5ac2d3784f385f03213ea8882edafe47bf88b3cd0f120f441f9246348fb2d75b6799f8548b021b04b"
def get_params(data):
first = enc_params(data, g)
second = enc_params(first, i)
return second
def to_16(data):
pad = 16 - len(data) % 16
data += chr(pad)*pad
return data
def enc_params(data, key):
iv = '0102030405060708'
data = to_16(data)
aes = AES.new(key=key.encode("utf-8"), IV=iv.encode('utf-8'), mode=AES.MODE_CBC)
bs = aes.encrypt(data.encode('utf-8'))
return str(b64encode(bs), "utf-8")
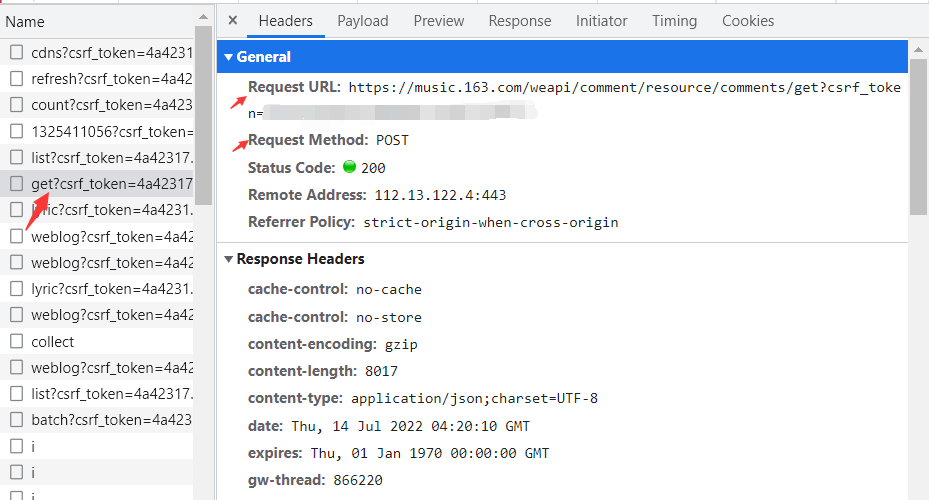
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token=4a42317491b25188649cd33d5ccfe8c4'
"""
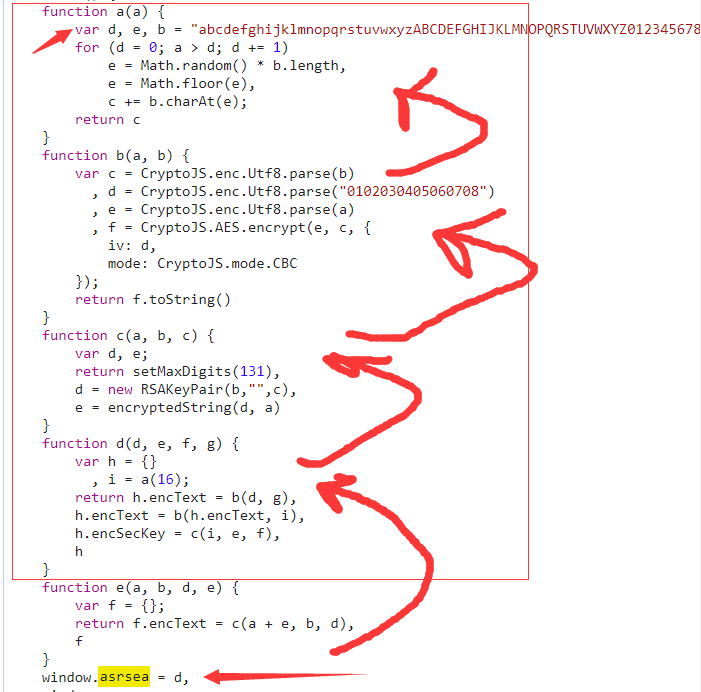
function a(a) { # 返回随机16位字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1) # 循环16次
e = Math.random() * b.length, # 随机数
e = Math.floor(e), # 取整
c += b.charAt(e); # 取字符串
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b) # b是秘钥
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a) # e是数据
, f = CryptoJS.AES.encrypt(e, c, { # c是加密的秘钥
iv: d, # 偏移量
mode: CryptoJS.mode.CBC # 加密模式
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16); # i是16位随机字符串
return h.encText = b(d, g), # g是秘钥
h.encText = b(h.encText, i), # 返回params,i是秘钥
h.encSecKey = c(i, e, f), #得到encSecKey 8===D 此时i已经是一个定制,所以可def一个函数get_encSecKey
h
}
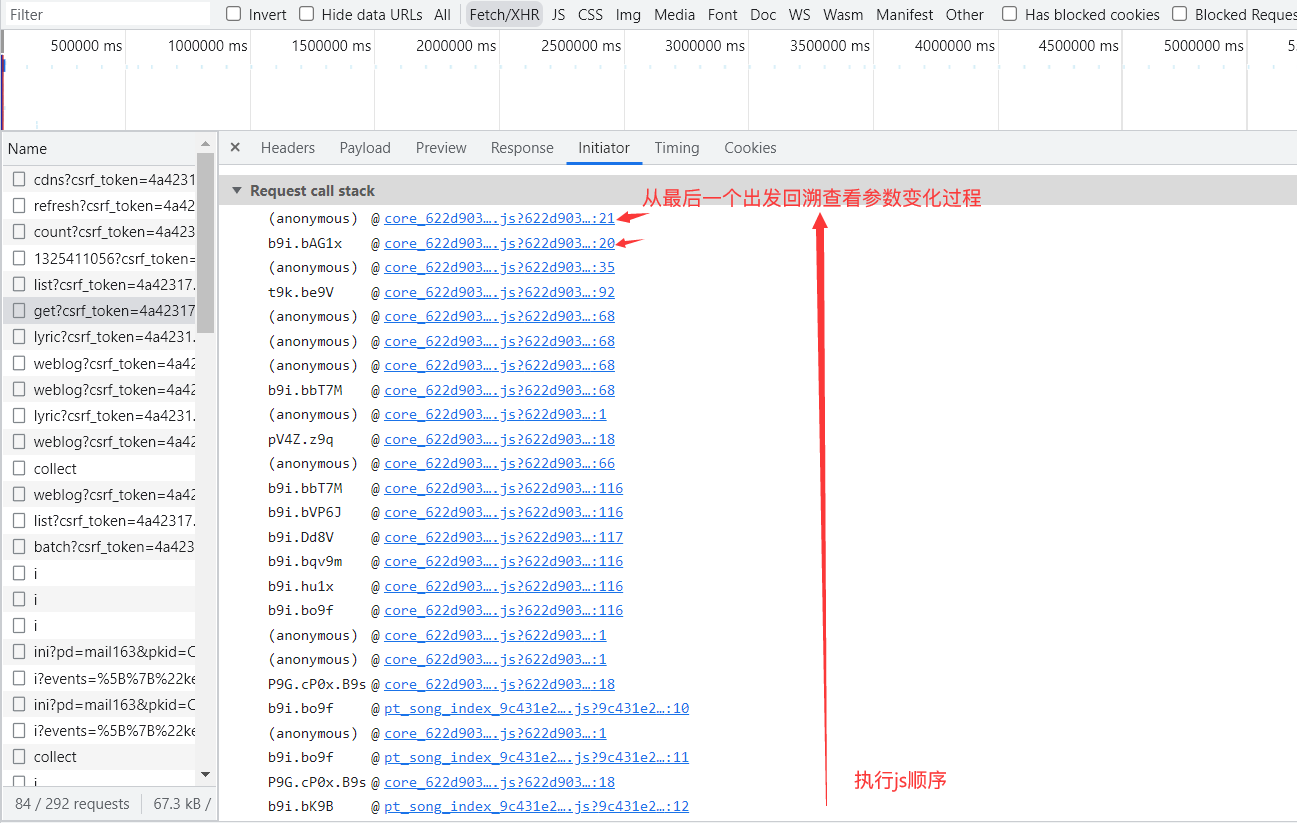
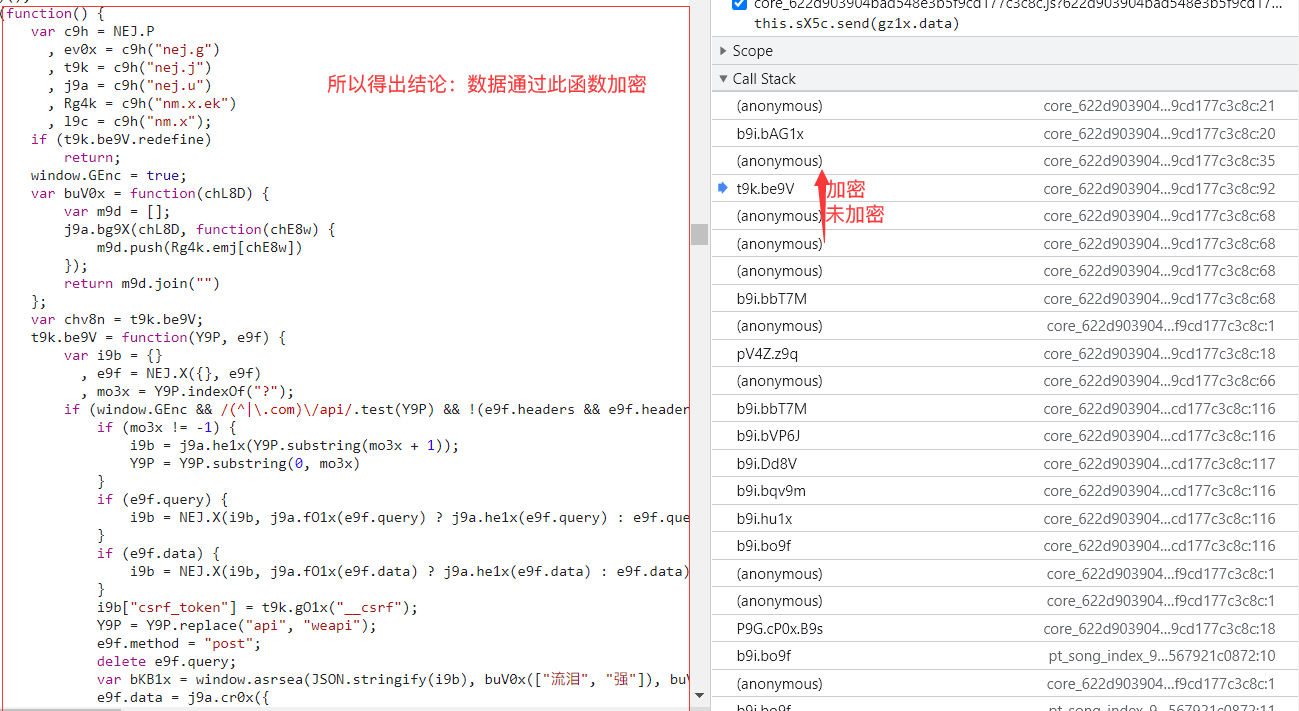
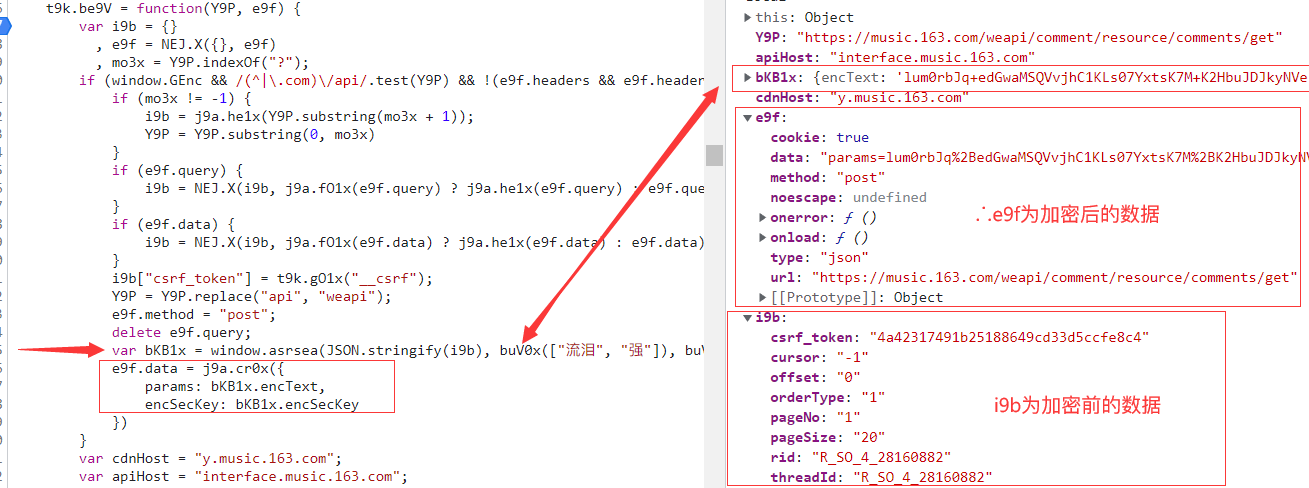
具体调用: var bKB1x = window.asrsea( d=JSON.stringify(i9b), e=buV0x(["流泪", "强"]), f=buV0x(Rg4k.md), g=buV0x(["爱心", "女孩", "惊恐", "大笑"]));
d:数据,e
"""
resp = requests.post(url, data={
"params": get_params(json.dumps(data)),
"encSecKey": get_encSecKey()
})
print(resp.json())
|