
浏览器渲染过程
简单渲染前过程描述
- 用户输入域名,DNS解析域名为IP地址
- 浏览器根据IP地址请求服务器
- 服务器响应HTTP请求,并返回数据给浏览器
- 浏览器开始渲染
具体细节:
当用户输入域名URL后,浏览器进程(一般一个标签页对应一个单独的进程,但是一些空白页会被合并为一个进程)中的
UI线程会建立一个网络线程,网络线程会根据DNS对域名进行解析获取IP(如果用户输入的是一些关键字/本地文件路径,就会到对应的搜索引擎/本地文件)。得到IP后,浏览器的SafeBrowsing会对IP进行安全检查(是否在黑名单),如果判定为不安全会提供一个禁止访问 的页面,如果安全将与服务器进行通信(TCP三次握手,返回响应报文)通知UI线程进行下一步工作。UI线程此时将新建一个渲染进程,并且通过IPC管道传输HTML文件给渲染进程的主线程,此时,正式开始渲染。
🏊♂️主线程
在
主线程中,会将HTML文件进行词法分析转义为Token,即Tokenization(标记化)并且创建
DOM节点,最后创建成DOM树上述 1,2 被称为HTML解析
但解析过程中,可能遇到
<link>与<style>,就会涉及到CSS的解析(为了提升解析效率,浏览器在解析前会启动一个预解析,会优先下载css与js的资源文件。当CSS文件还未下载的时候,主线程并不会阻塞,这是因为CSS的下载与解析是在预解析线程中执行的,CSS解析完成后将生成CSSOM树。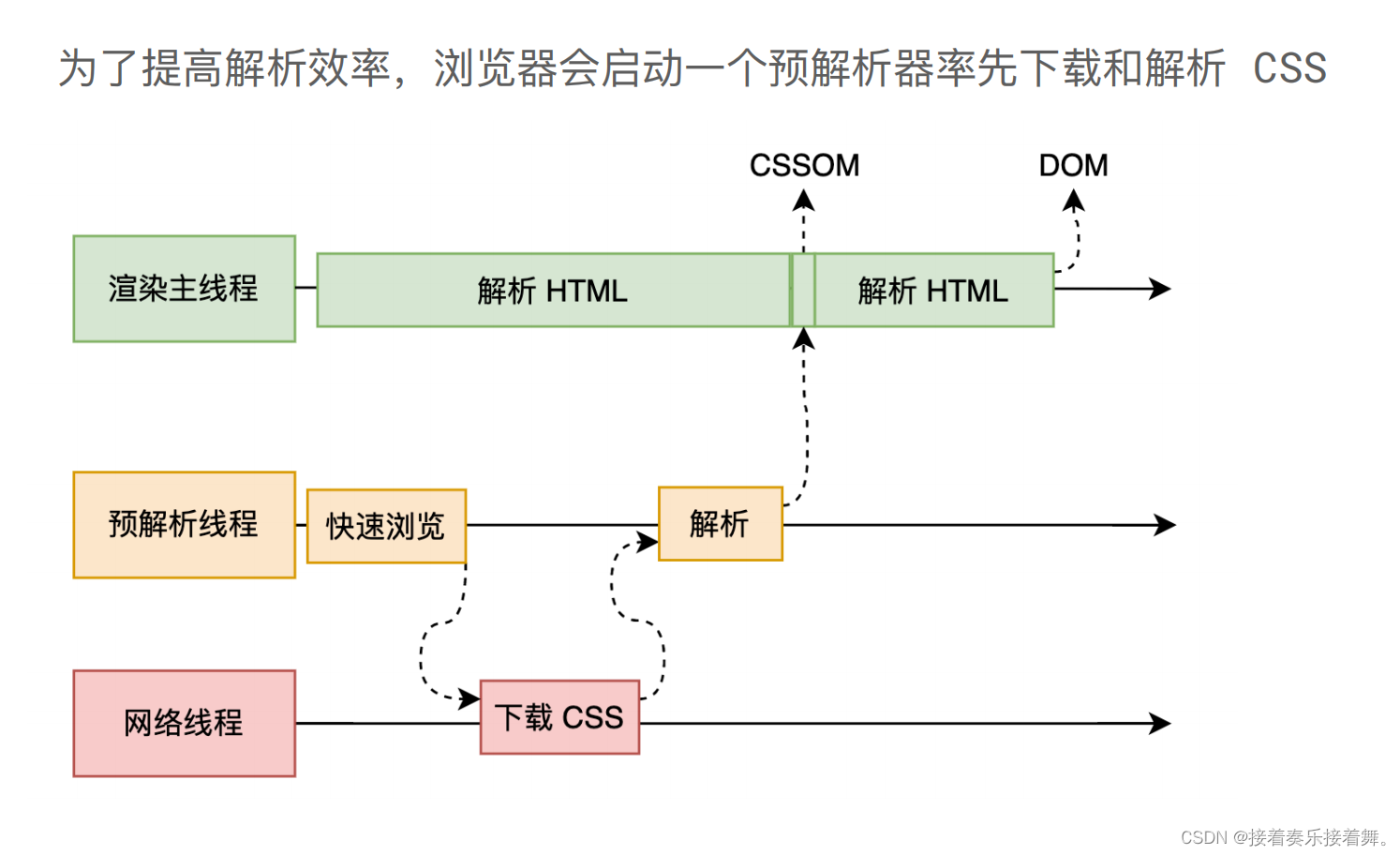
解析过程中,可能遇到
<script>等标签,这就涉及到了JS的解析,而JS的解析会阻塞当前的HTML解析,在JS解释完毕后再继续,这是因为我们不清楚JS是否会操作DOM节点或者操作CSS节点。因此,我们需要注意JS的引入时间,一般JS的加载位置应该放在BODY标签的底部,或者使用
Defer。此时,我们已经得到了解析好的
DOM树与CSSOM树,此时进行Computed Style,得到一棵带有样式的DOM但是还不够,我们还需要得到
Layout来获取每个节点的几何信息,通过这个计算过程后,我们将得到一棵带有页面x,y坐标以及盒子尺寸的Layout Tree,此时Layout Tree与我们真实能看到的内容是一一对应的了。Layout Tree与DOM并非一一对应,其中不可视的display: none不会在Layout Tree上,而伪类元素(::before等)会挂载在Layout Tree的相应节点但是仍然不够,此时还需要注意,如果两个节点的位置大小有重合的话,我们无法确定哪个节点展示在前,哪个被覆盖,因此我们还需要确认各个节点的
绘制顺序,即分层。分层工作完成后,将生成绘制指令,将每个层单独生成绘制指令。==只是生成,并未执行==
🏊♀️合成线程
合成线程会先对图层进行分块处理得到
Tiles(会从线程池获取栅格线程的帮助)分块完成后,将进行光栅化阶段,这一过程会交付给GPU进程,最终得到位图。
最后,当所有的图块都被栅格化后,合成线程将生成一个个指引quad信息,并通过
IPC给浏览器进程发送一个渲染帧,这个渲染帧最终将交由GPU进行显示,每当页面滚动的时候,合成线程都会交付另一个渲染帧给GPU来更新页面。指引会标识位图的位置,以及考虑旋转,缩放平移等信息,与渲染主线程无关。这就是为什么
transform效率高的本质原因,以及不会引起回流(重排)与重绘阻塞渲染。
相关问题
1. Reflow 回流/重排
当进行影响
Layout Tree的操作的时候,需要重新计算Layout Tree,而且为了避免连续的多次布局反复计算,浏览器会合并这些操作,当JS代码全部完成后再统一计算,改动属性造成的Reflow是异步完成的。也正因如此,JS获取布局属性的时候可能会无法获取到最新的布局信息。2. Repaint 重绘
重绘,重新绘制渲染树,一般不影响DOM树,不一定引起回流,而回流一定引起重绘。
